
10. 네번째 딥러닝 - 신경망의 완성 : 히든레이어
https://www.opentutorials.org/module/4966/28988
네번째 딥러닝 - 신경망의 완성:히든레이어 - Tensorflow 1
수업소개 히든레이어와 멀티레이어의 구조를 이해하고, 히든레이어를 추가한 멀티레이어 인공신경망 모델을 완성해 봅니다. 강의 멀티레이어 신경망 실습 소스코드 colab | backend.ai 보스
www.opentutorials.org
요약정리
1. 강의
딥러닝을 이해하기 위한 마지막 단계
퍼셉트론 하나로 만들어진 모델 말고 퍼셉트론을 깊게 연결한 모델을 공부해보자
입력부분을 input layer 이고 출력을 output layer
입력부분에서 hidden layer를 보면 13개의 입력을 받아 5개의 출력을 내는것
hidden layer 에서 output layer 로 보면 5개의 입력을 받아 1개의 출력을 내느 ㄴ것
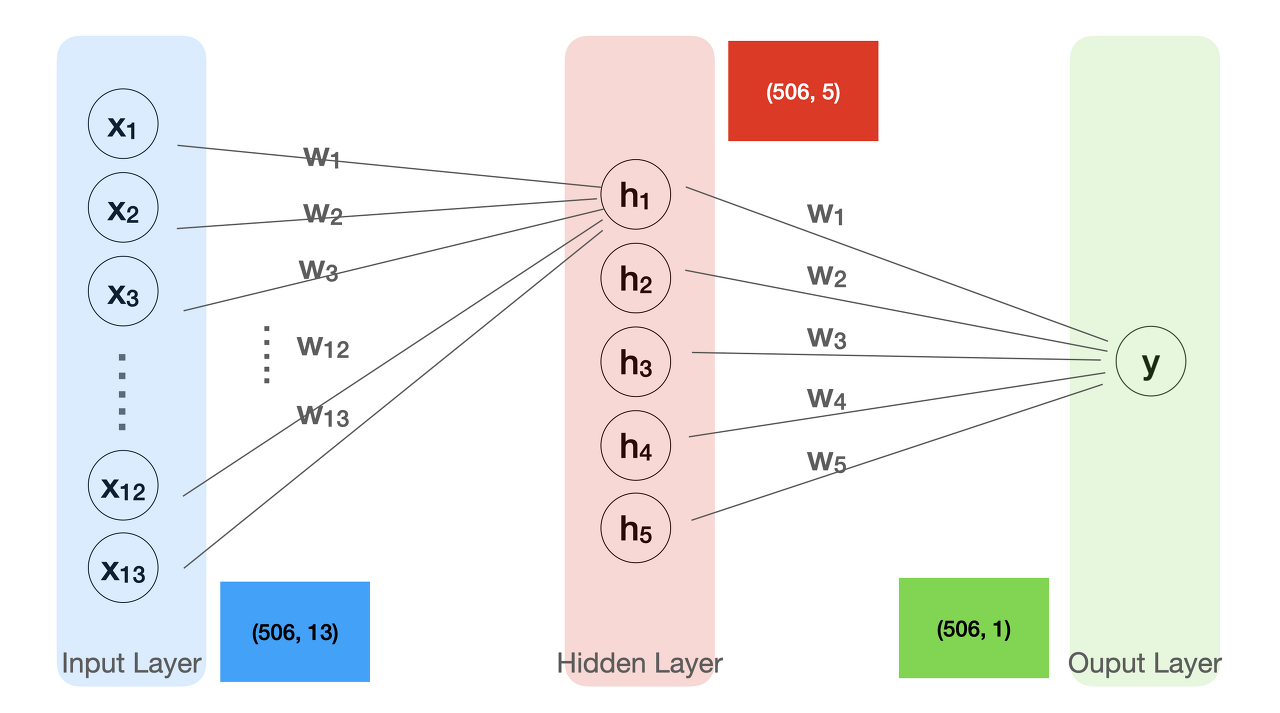
모델을 만드는 코드를 살펴보면 아래와 같다.
X = tf.keras.layers.Input(shape[13])
H = tf.keras.layers.Dense(5,activation = 'swish')(X)
Y = tf.keras.layers.Dense(1)(H)
model=tf.keras.models.Model(X,Y)
model.compile(loss='mse')
H의 activation function 으로 'swish' 가 쓰였는데 최근에 나온 활성함수로 성능이 이전의 다른 함수보다 좋음
hidden layer를 여러개를 더 쌓아보자 .
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(5, activation='swish')(X)
H1 = tf.keras.layers.Dense(3, activation='swish')(H)
H2 = tf.keras.layers.Dense(3, activation='swish')(H1)
Y = tf.keras.layers.Dense(1)(H2)
model = tf.keras.models.Model(X,Y)
model.compile(loss='mse')위의 경우는 hidden layer가 1개가 아니고 3개인 경우의 코드이다. H1와 H2의 경우 3개의 노드를 가진 layer이다.
2. 실습
이전에 했던 boston 데이터와 iris 데이터로 실습해보자
import pandas as pd
import tensorflow as tf
# 과거의 데이터를 준비한다
bostonfile = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
boston = pd.read_csv(bostonfile)
print(boston.columns)
boston.head()
#데이터 분리작업
independ = boston[['crim','zn','indus','chas','nox','rm','age','dis','rad','tax','ptratio','b','lstat']]
depend = boston[['medv']]
print(independ.shape, depend.shape)
# 모델의 구조를 만든다(기존코드)
X=tf.keras.layers.Input(shape=[13])
Y=tf.keras.layers.Dense(1)(Y)
model=tf.keras.models.Model(X,Y)
model.compile(loss='mse')
#hidden layer를 쌓은 모델의 구조
#H 하나로 해서 쌓아도 되는데 구별을 위해 번호를 매겨서 layer를 쌓았다.
X=tf.keras.layers.Input(shape=[13])
H=tf.keras.layers.Dense(10,activation="swish")(X)
H1=tf.keras.layers.Dense(10,activation="swish")(H)
H2=tf.keras.layers.Dense(5, activation='swish')(H1)
H3=tf.keras.layers.Dense(3,activation='swish')(H2)
H4=tf.keras.layers.Dense(3, activation='swish')(H3)
Y=tf.keras.layers.Dense(1)(H4)
model=tf.keras.models.Model(X,Y)
model.compile(loss='mse')
# 데이터로 모델을 학습(fit) 시킨다
model.fit(independ,depend,epochs=500)
model.fit(independ,depend,epochs=500)
model.fit(independ,depend,epochs=500,verbose=0)
#모델에 대한 확인작업
model.summary()
#입력층은 13->10->5->3->3->1
#파라미터(Param#)가 가중치이다. 맨처음 입력 13개 -> weight와 bias 합치면 수식마다 14개의 가중치가 필요
# 모델이용하기
model.predict(independ[0:5])
depend[0:5]
# 모델의 수식 확인 (weight와 bias 확인)
model.get_weights()
iris 데이터도 비슷한 방식으로 코드진행
11. 부록1 : 데이터를 위한 팁
https://www.opentutorials.org/module/4966/28989
부록1: 데이터를 위한 팁 - Tensorflow 1
수업소개 데이터 타입의 문제와 NA값의 문제를 해결하는 데이터 전처리 방법을 배웁니다. 강의 소스코드 colab | backend.ai ########################### # 라이브러리 사용 import pandas as pd ###################
www.opentutorials.org
데이터를 다룰 때 생기는 문제해결팁
문제 1. 원핫인코딩을 할 때 변수의 데이터타입때문에 발생하는 문제
import pandas as pd
irisfile="https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris2.csv"
iris = pd.read_csv(irisfile)
iris.head()
#iris2 데이터는 기존iris데이터와 품종 부분이 다르다. (iris2는 숫자로 표현되어있음)

# 원핫인코딩
encoding = pd.get_dummies(iris)
encoding.head()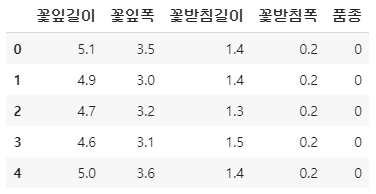
pandas는 숫자의 형태인데 범주형이면 숫자로 인식해버리기때문에 원핫인코딩이 되지 않는다.
그렇다면 iris데이터셋의 데이터 타입을 한 번 확인해보자
print(iris.dtypes)
우리가 원핫인코딩을 해야하는 '품종'칼럼이 범주형이 아니라 숫자형(int64)임을 확인할 수 있다.
우리가 원하는대로 원핫인코딩을 진행해야하면 어떻게 해야할까?
1. '품종'칼럼의 타입을 범주형을 바꿔준다.
iris['품종']=iris['품종'].astype('category')2. 바뀐 타입을 확인한 후 원핫인코딩을 진행한다.
print(iris.dtypes)
encoding = pd.get_dummies(iris)
encoding.head()
문제 2. 데이터 안에 내용중 NA(Not Available)값 때문에 발생하는 문제
1. 먼저 데이터셋안에 NA값이 있는지 확인부터 해본다.
iris.isna().sum()
isna().sum() 하게되면 칼럼별로 NA값의 총계가 나온다!
iris데이터에서는 '꽃잎폭' 칼럼에 하나의 NA값이 있음을 확인할 수 있다.
iris.tail()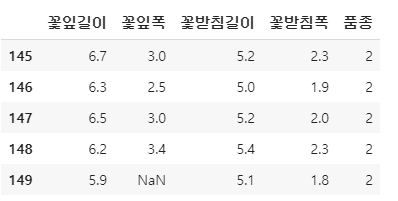
이 데이터셋에는 맨 밑에 NA값이 있어서 tail() 함수로 NA값을 직접 확인할 수 있다.
NA값을 수정하지않고 그냥 모델에 넣어버리게 되면 모델은 이 값을 알 수가 없어서 에러가 발생한다. 따라서 데이터전처리과정을 통해서 미리 수정해두는 것이 좋다.
NA값을 우리가 흔히 결측치라고도하고 이상치(outlier)라고도 하는데NA값은 0과는 다른 값이다. 0은 아니고 그냥 빈 값 ,없는 값을 NA이라고 한다. 이 NA값은 보통 없애거나 다른 값으로 바꿔준다. 하지만 NA값을 없애는건 NA값이 속한 행 하나를 없애는 것이므로 위험하다. 따라서 0 으로 바꾼다던가 아니면 그 칼럼의 평균값으로 치환해주는 경우가 대부분이다. 이번 실습에서는 NA값에 '꽃잎폭' 평균 값을 넣어주는 방법으로 진행한다.
mean=iris['꽃잎폭'].mean()
iris['꽃잎폭']=iris['꽃잎폭'].fillna(mean)mean()함수를 이용해 '꽃잎폭' 칼럼의 평균값을 mean 변수에 넣고, fillna()함수를 이용해 NA값을 아까 정한 mean변수의 값으로 바꿔준다.
iris.tail()
아까 NaN이었던 값이 '꽃잎폭'칼럼의 평균값으로 대체되어있는 것을 확인할 수 있다!
12. 부록2 : 모델을 위한 팁
https://www.opentutorials.org/module/4966/29242
부록2: 모델을 위한 팁 - Tensorflow 1
수업소개 BatchNormalization layer를 사용하여 보다 학습이 잘되는 모델을 만들어 봅니다. 강의 소스코드 colab | backend.ai 보스턴 집값 예측 ########################### # 라이브러리 사용 import tensorflow as
www.opentutorials.org
모델이 조금 더 잘 학습하게 하기위한 작업을 소개한다.
비교를 위해 이전에 사용했던 boston 학습모델을 가지고오자!
import tensorflow as tf
import pandas as pd
bostonfile= 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
boston = pd.read_csv(boston)
independ = boston[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax','ptratio', 'b', 'lstat']]
depend = boston[['medv']]
print(independ.shape, depend.shape)
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
model.summary()
model.fit(independ, depend, epochs=100)
print(model.predict(independ[:5]))
print(depend[:5])
X=tf.keras.layers.Input(shape=[13])
Y=tf.keras.layers.Dense(1)(X)
model=tf.keras.models.Model(X,Y)
model.compile(loss='mse')원래 boston 모델에서는 hidden layer 없이 input 과 output 레이어로만 이루어져 있었다.
이 코드를 조금 더 학습이 잘되게끔 중간에 hidden layer를 넣어보자
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8, activation='swish')(X)
H1 tf.keras.layers.Dense(8, activation='swish')(H)
H2= tf.keras.layers.Dense(8, activation='swish')(H1)
Y = tf.keras.layers.Dense(1)(H2)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')H = tf.keras.layers.Dense(8, activation='swish')(X)
H1 = tf.keras.layers.Dense(8, activation='swish')(H)
H2 = tf.keras.layers.Dense(8, activation='swish')(H1)여기서 hidden layer인 부분을 두 개로 쪼갤 수 있다.
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.Activation('swish')(H)
H1 = tf.keras.layers.Dense(8)(H)
H1 = tf.keras.layers.Activation('swish')(H1)
H2 = tf.keras.layers.Dense(8)(H1)
H2 = tf.keras.layers.Activation('swish')(H2)이 두 줄은 위의 코드랑 같은 결과를 낸다. 그런데 이렇게 두 줄로 분리한 이유는 batchnormalization을 하기위함인데,
batchnormalization을 저 두 줄 사이에 넣게 되면 효과적이다. 즉, 더 잘 학습할 수 있게되는 것이다.
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H1 = tf.keras.layers.Dense(8)(H)
H1 = tf.keras.layers.BatchNormalization()(H)
H1 = tf.keras.layers.Activation('swish')(H1)
H2 = tf.keras.layers.Dense(8)(H1)
H2 = tf.keras.layers.BatchNormalization()(H1)
H2 = tf.keras.layers.Activation('swish')(H2)

loss가 많이 떨어졌음을 알 수 있다. (더 잘 학습이 된 것! )
batchnormalization은 분류모델에서도 적용이 가능하다 . 밑의 코드는 iris 데이터에서 적용해본 결과임
irisfile= 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv'
iris = pd.read_csv(irisfile)
iris= pd.get_dummies(iris)
independ = iris[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
depend = iris[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(independ.shape, depend.shape)
X = tf.keras.layers.Input(shape=[4])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H1 = tf.keras.layers.Dense(8)(H)
H1 = tf.keras.layers.BatchNormalization()(H)
H1 = tf.keras.layers.Activation('swish')(H1)
H2 = tf.keras.layers.Dense(8)(H1)
H2 = tf.keras.layers.BatchNormalization()(H1)
H2 = tf.keras.layers.Activation('swish')(H2)
Y = tf.keras.layers.Dense(3, activation='softmax')(H2)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')
model.fit(independ, depend, epochs=1000)
13. 수업을 마치며
https://www.opentutorials.org/module/4966/28990
수업을 마치며 - Tensorflow 1
수업소개 마지막 수업 영상입니다. 강의
www.opentutorials.org
텐서플로우 완강!
야호~
'Study > 생활코딩 머신러닝야학' 카테고리의 다른 글
| [생활코딩 머신러닝야학] 텐서플로우 Day4 (0) | 2020.08.26 |
|---|---|
| [생활코딩 머신러닝야학] 텐서플로우 Day3 (0) | 2020.08.19 |
| [생활코딩 머신러닝야학] 텐서플로우 Day2 (0) | 2020.08.18 |
| [생활코딩 머신러닝야학] 텐서플로우 Day1 (0) | 2020.08.18 |
| [생활코딩 머신러닝야학] 머신러닝야학 OT (0) | 2020.08.13 |