CNN(Convolutional Neural Network)은 음성 인식이나 이미지 인식에 주로 사용되는 신경망의 한 종류이다.
다차원 배열 데이터를 처리하도록 구성되어 있어, 컬러 이미지같은 다차원 배열 처리에 특화되어있다.
이미지 인식 분야에서 딥러닝을 활용한 기법은 대부분 CNN을 기초로 한다.
1. 합성곱 신경망 CNN(Convolutional Neural Network)
CNN은 필터링 기법을 인공신경망에 적용함으로써 이미지를 더욱더 효과적으로 처리하기 위해 1989년 처음 소개되었고 1998년, 현재 딥러닝에서 사용하는 형태의 CNN이 제안되었다.

기존 필터링 기법은 위의 그림과 같이 고정된 필터를 이용해 이미지를 처리했다.
CNN의 기본 개념은 "행렬로 표현된 필터의 각 요소가 데이터 처리에 적합하도록 자동으로 학습하게 하자"이다.
예를 들어 이미지를 분류하는 알고리즘을 개발하고자 할 때 우리는 필터링 기법을 이용해 분류 정확도를 향상시킬 수 있을것이다. 그러나 한가지 문제점은 사람의 직관이나 반복적인 실험을 통해 알고리즘에 이용될 필터를 결정해야한다는 것이다. 알고리즘에 필요한 필터까지 자동으로 학습하게 하려면 CNN을 사용하면 된다.
(CNN이 이미지 분류 정확도를 최대화하는 필터를 자동으로 학습할 수 있기 때문임)
1.1 CNN의 구조
일반적인 인공신경망은 affline 으로 명시된 fully-connected 연산과 ReLU와 같은 비선형 활성 함수(nonlinear activate function) 의 합성으로 정의된 계층을 여러개로 쌓은 구조이다.

CNN은 밑의 사진과 같이 합성곱 계층(convolutional layer)과 풀링 계층(pooling layer) 이라고 하는 새로운 층을 fully-connected 계층 이전에 추가함으로써 원본 이미지에 필터링 기법을 적용한 다음 필터링된 이미지에 대핸 분류연산이 수행되도록한다.

합성곱 계층은 이미지에 필터링 기법을 적용하고, 풀링 계층은 이미지의 국소적인 부분들을 하나의 대표적인 스칼라 값으로 변환함으로써 이미지의 크기를 줄이는 등 다양한 기능을 수행한다.
합성곱 계층 -> 이미지 필터링
ReLU 계층 -> 비선형 활성함수
풀링 계층 -> 이미지의 작은 부분들을 대표 스칼라값으로 변환(이미지의 크기를 줄여줌)
왜 활성화 함수를 쓰는 걸까?
활성화 함수의 특징은 비선형(nonlinear) 함수라는 것이다.
선형함수는 입력값에 상수배를 한 결과를 출력해주는데 선형함수를 가지고는 직선밖에 그릴 수 없다.
인공신경망의 성능을 향상시키기 위해서는 많은 은닉층(Hidden-Layer)가 필요한데 활성화 함수를 선형함수로 하게되면 은닉층을 계속 쌓을 수 없다. 선형함수로는 은닉층을 여러번 추가하더라도 1회 추가한 것과 별 반 차이가 없다는 것이다. 그렇다고 선형함수를 사용한 것이 아무 의미가 없는 것은 아니다. (학습가능한 가중치가 달라진다는 점에서 의의가 있다) 이와 같이 선형함수를 사용한 층을 활성화 함수를 사용한 은닉층과 구별하기 위해 선형층(linear layer) 또는 투사층(projection layer)라고 한다. 활성화 함수를 사용하는 일반적인 은닉층은 선형층과 대비되는 비선형층(nonlinear layer)이다. 가장 많이 쓰는 활성화 함수는 sigmoid function / Hyperbolic tangent function / ReLU function 이 있다.
(1) sigmoid function (=logistic function)

sigmoid의 특징
-함수값이 (0,1) 사이의 값으로 제한된다.
-중간값이 0.5이다
-매우 큰 값을 가지면 함수값은 거의 1이 되고, 매우 작은 값을 가지면 거의 0이 된다.
이러한 특징 때문에 맨처음에 활성함수로 많이 쓰였지만 최근에 문제점이 발생하면서 잘 사용하지 않는다
-Gradient Vanishing
: sigmoid 함수 그래프를 보면 출력값(sigmoid(x))이 0 또는 1에 가까워질 때 기울기가 아주 완만해진다. 기울기를 계산해보면 0에 가까운 아주 작은 값이 나온다. 역전파(Backpropagation)에서 이렇게 0에 가까운 아주 작은 기울기가 곱해지게 되면 그 앞 층에 기울기가 제대로 전달이 잘 안된다. 이러한 현상을 Gradient Vanishing이라고 한다.
(2)Hyperbolic tangent function
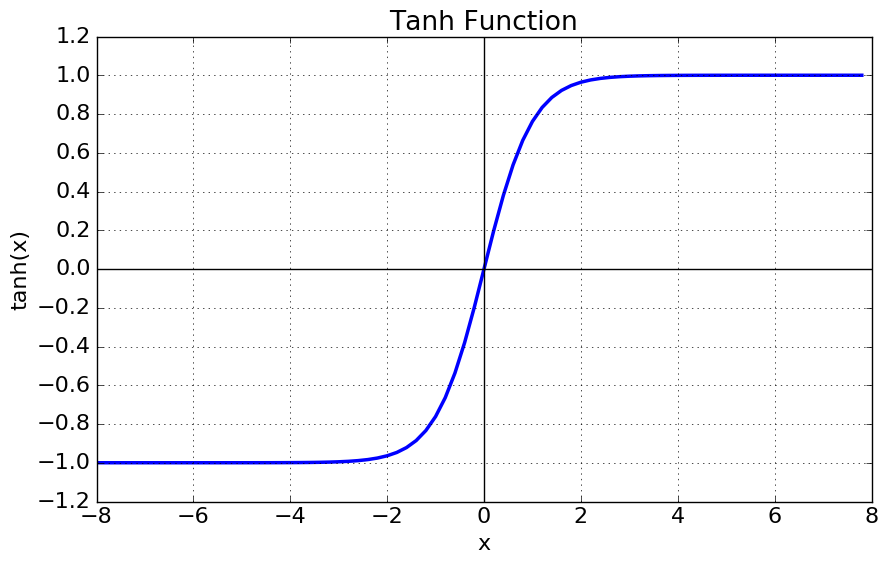
tanh 의 특징
- 함수의 중심값을 0으로 옮겨 sigmoid의 최적화 과정이 느려지는 문제점을 해결
- 하지만 미분함수에 대해서 일정값 이상으로 커지게 되면 미분값이 없어지는 gradient vanishing 문제점은 남아있음
(3) ReLU(Reactified Linear Unit) function
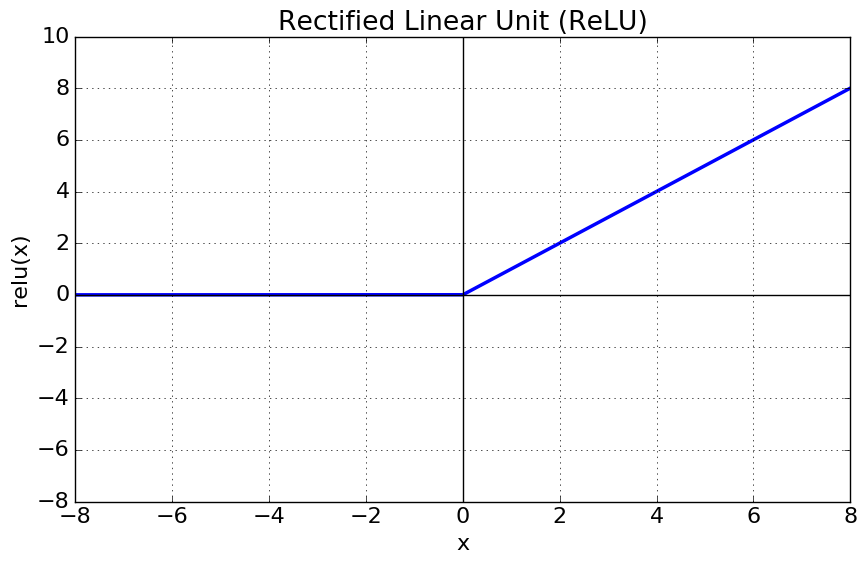
ReLU의 특징
- x>0이면 기울기가 1인 직선이고, x<0이면 함수값이 0이 된다.
- sigmoid와 tanh에 비해 학습이 훨씬 빠르다
- 연산비용이 크지 않고 구현도 매우 간단하다.
- x<0인 값들에 대해서는 기울기가 0이기 때문에 뉴런이 죽을 수도 있다는 단점이 있다.
ReLU의 단점을 보완하기 위해 Leakly ReLU , PReLU, Exponential Linear Unit (ELU) 등이 등장
1.2 합성곱 계층 (Convolutional Layer)
(1) 합성곱 계층
- 합성곱 신경망(CNN) 계층은 형상을 유지한다. 만약 이미지와 같은 3차원 데이터를 입력받으면 다음 계층에서도 3차원 데이터로 전달하는 것이다. 따라서 합성곱 신경망에서는 이미지처럼 형상을 가진 데이터를 제대로 이해할 수 있다.
(데이터의 모습, 형상이 그대로 유지되기 때문이다)
- 합성곱 신경망에서 합성곱 계층의 입출력 데이터는 다차원이라서 이것을 특징 맵 (Feature Map)이라고 한다. 입력 데이터를 입력 특징 맵(Input Feature Map), 출력 데이터를 출력 특징 맵(Output Feature Map) 이라고 한다.
(2) 합성곱 연산 (Convolution)

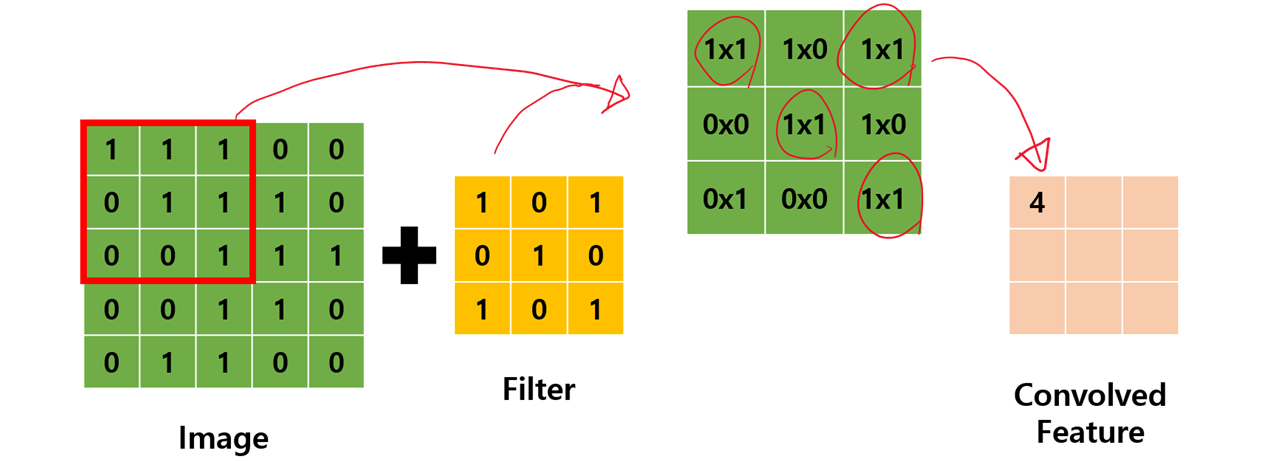

- 합성곱 계층에서는 합성곱 연산을 수행한다. 이 연산은 이미지 처리에서 말하는 필터연산에 해당한다. 위 그림과 같이 2차원의 입력 데이터가 들어오면, 필터의 윈도우를 일정 간격(Stride)으로 이동해가며 입력 데이터에 적용한다. 입력과 필터에서 대응한 원소기리 곱한다음 합을 구하면 그 결과가 출력되는 형식이다. 이 과정을 모든 데이터에서 수행하면 합성곱 연산의 출력이 완성된다.
- 스트라이드(stride) : 필터를 적용하는 위치의 간격을 스트라이드(stride)라고 한다. 스트라이드가 커지면 필터의 윈도우가 적용되는 간격이 넓어져 출력 데이터의 크기가 줄어든다.
*stride는 꼭 가로로만 움직여야하나? 세로로 stride를 적용할 수는 없는건가?
(3) 패딩 (Padding)
-패딩(Padding)은 합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정값(0,1)로 채우기도 하는데 이를 패딩이라고 한다. 합성곱 연산에서 자주 사용되는 기법이다.

- zero-padding 은 연산이나 데이터 특징에 영향을 주지 않는다는 특징이 있다. 또 padding을 하게되면 convolution을 해도 크기가 작아지지 않는다는 장점이 있다.
- 왜 padding이라는 과정을 거치는 것일까?
convolution 을 진행하면 이미지의 크기가 압축이 되어서 점점 작아지는데 이렇게 되면 끝에 위치한 픽셀들의 정보가 점점 없어지는 문제점이 생긴다. 즉, 가장자리에 위치한 정보들을 포함하기 위해 padding 진행. padding을 하게되면 입력 데이터의 공간적 크기를 고정한 채로 다음 계층에 전달할 수 있기 때문이다.
(4) 3차원 데이터의 합성곱 연산

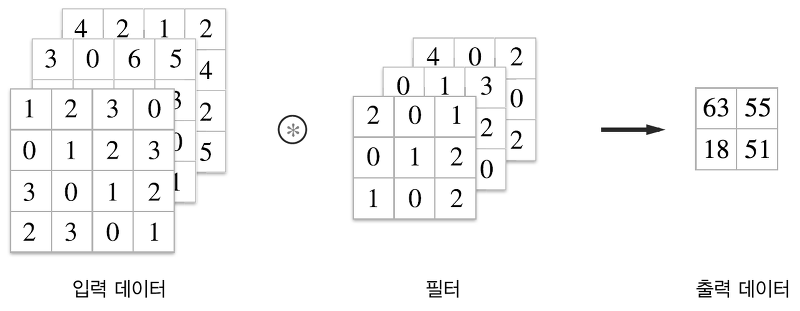
- 채널까지 고려한 3차원 데이터도 2차원 데이터와 동일한 방식으로 작동한다. 다만 주의할 점은 3차원의 합성곱 연산에서는 입력 데이터의 채널 수와 필터의 채널 수가 같아야한다는 것이다. 또한 필터의 크기는 임의로 설정할 수 있으나, 모든 채널의 필터가 같은 크기여야한다.
1.3 풀링 계층 (Pooling Layer)

-풀링(Pooling) 계층 : 이미지의 크기를 계속 유지한 채 Fully-connected layer로 넘어가면, 모델이 수행해야하는 연산량이 엄청 늘어나게 된다. 적당하게 크기를 줄이면서 특정 feature를 강조해야하는데 그 역할을 Pooling Layer에서 진행
-풀링(Pooling)에 여러 방법이 있는데 그 중에서 max pooling이 주로 사용되는 방법이다. 우리 몸에 있는 신경도 가장 큰 신호에 반응한다는 점과 유사하다 이렇게 되면 데이터의 노이즈도 감소하고, 속도도 빨라지며, 영상의 분별력도 높아진다.
-풀링 계층의 특징으로, 풀링 연산은 입력 데이터의 채널 수 그대로 출력 데이터로 보낸다는 점이다. 풀링은 2차원 데이터의 크기를 줄이는 연산이라 3차원을 결정하는 채널 수는 건드리지 않는다. 따라서 채널마다 독립적으로 계산한다.
- 또한 풀링 계층은 입력의 변화에 영향을 적게 받는다는 점이다. 입력 데이터가 조금 변하더라도 풀링 계층 자체가 그 변화를 흡수해 사라지게 할 수 있기 때문이다.
2. CNN vs FNN
이미지 또는 음성 데이터를 FNN알고리즘을 가지고 학습하면 안되는걸까? CNN알고리즘을 써야하는 이유는?

2.1 인접 픽셀 간의 상관관계 무시
- FNN알고리즘은 벡터형태로 표현된 데이터를 입력데이터로 받기 때문에 이미지 데이터를 벡터화하는 과정이 필요하다. 보통의 이미지 데이터는 인접 픽셀 간 높은 상관관계를 가지고 있는 것이 특징이다. 이를 벡터화하는 과정에서 픽셀 간의 상관관계가 무시되고 정보의 손실이 발생하게 된다.
2.2 방대한 양의 model parameter
-CNN의 경우 fully-connected layer로 넘어가기 전 convolution, pooling, filter 등의 방법으로 알고리즘이 학습해야하는 parameter 양을 줄여준다. 하지만 FNN은 그러한 과정이 없기 때문에 바로 이미지 데이터를 사용하게 되면 알고리즘이 학습해야하는 parameter의 양이 너무 많다는 문제가 있다.
참고한 사이트
CNN개념 (https://untitledtblog.tistory.com/150)
필터 종류 사진 (https://en.wikipedia.org/wiki/Kernel_(image_processing))
활성함수 + 사진 (https://reniew.github.io/12/)
활성함수 (https://wikidocs.net/60683)
합성곱 연산 (https://excelsior-cjh.tistory.com/180)
합성곱 계층 설명( https://kolikim.tistory.com/53)
'Study > Deep Learning' 카테고리의 다른 글
| [딥러닝/Deep Learning] TensorFlow 윈도우 설치 (0) | 2020.07.23 |
|---|