[Python/ Data Science] 데이터프레임 라이브러리 Polars

데이터 분석하다가 도저히 해도 모르겠어서 때려치고 쓰는 블로그
이번 데이터 분석에서 사용한 Polars에 대해서 소개해보려고한다.

데이터를 만지려면 습관처럼 쓰는 pandas를 대체할 수 있는 라이브러리가 작년 릴리즈 되었다.
1. Pandas 있는데 굳이 Polars 를 써야하는 이유가 있을까?
(1). Polars의 가장 큰 장점은 바로 '빠르다' 는 것이다.

Polars의 공식 문서에서도 가장 먼저 언급하고 있는 점이 바로 빠르다는 것이다.

실제로 (20000,23) 사이즈의 데이터를 가지고 올 때 Polars 는 11ms 가 소요되었고 Pandas 는 59ms가 소요되었다.
데이터의 사이즈가 엄청 큰 경우 Pandas보다 Polars를 쓰는 것이 시간적 측면에서 더 이득이지 않을까 생각했다.
어떻게 Polars는 데이터를 불러오는데 시간을 단축할 수 있었을까?
1. 기계에 조금 더 가까운 Rust 언어로 작성됨
Rust 언어에 대해서 잘 몰라서 [노마드 코더의 Rust 언어 10분 정리 영상] 을 참고했다.
대략적으로 Rust 언어는 빠르고 안전한 Low - level Language! 그래서 Pandas 보다 작동 속도가 훨씬 빠르다.
2. 외부 dependencies를 제외함
pandas의 경우 설치할 때보면 'Requirement already satisfied'로 pandas 라이브러리 하나를 설치하기 위해 필요한 다른 라이브러리들이 존재한다. 즉 Pandas는 다른 외부 라이브러리의 영향을 받는다.

polars의 경우 polars 자체만 설치가 된다. 즉, 다른 라이브러리의 존재 여부와 상관없이 설치가 되므로 비교적 빠르게 동작할 수 있다.

(2). Polars의 두 번째 장점은 '직관적인 문법' 이다.
이건 내 개인적인 사용 후기이기도 한데, 기존 pandas 사용자들도 접근하기 쉽게 pandas 의 문법과 비슷하면서 조금 더 직관적인 문법이라고 느껴졌다. 아래 다루겠지만 데이터 프레임에서 특정 값을 가져올 때 select 로 가져올 수 있다는 것도 참신하고 직관적이어서 좋았다.
2. Pandas 와 Polars 비교하기
IDE : DataSpell
Version : Python 3.11
(1). import
- Pandas
#pip3 install pandas
import pandas as pd
- Polars
#pip3 install polars
import polars as pl
(2). 데이터 프레임 만들기
[Polars 공식 docs에 있는 예제 참고]
- Pandas
pd_df = pd.DataFrame({
"id": [9, 4, 2],
"place": ["Mars", "Earth", "Saturn"],
"date": pl.date_range(date(2022, 1, 1), date(2022, 1, 3), "1d", eager=True),
"sales": [33.4, 2142134.1, 44.7],
"has_people": [False, True, False],
"logged_at": pl.datetime_range(
datetime(2022, 12, 1), datetime(2022, 12, 1, 0, 0, 2), "1s", eager=True
),
})
print(pd_df)
- Polars
pl_df = pl.DataFrame(
{
"id": [9, 4, 2],
"place": ["Mars", "Earth", "Saturn"],
"date": pl.date_range(date(2022, 1, 1), date(2022, 1, 3), "1d", eager=True),
"sales": [33.4, 2142134.1, 44.7],
"has_people": [False, True, False],
"logged_at": pl.datetime_range(
datetime(2022, 12, 1), datetime(2022, 12, 1, 0, 0, 2), "1s", eager=True
),
}
).with_row_index("index")
print(pl_df)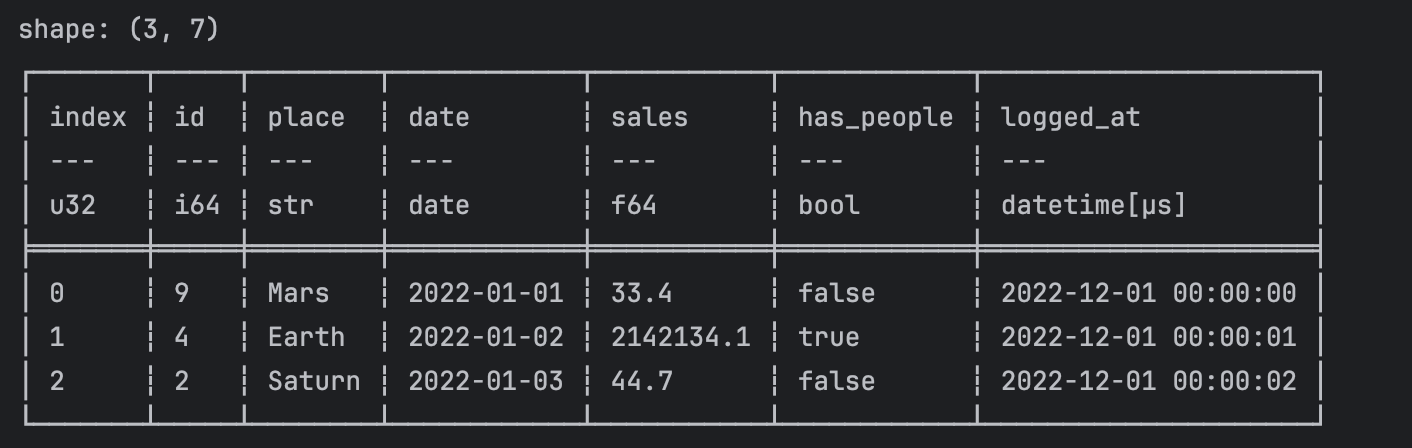
(3). 값 가져오기
- Pandas 에서 column 값 가져오기
print(pd_df[['place','sales']])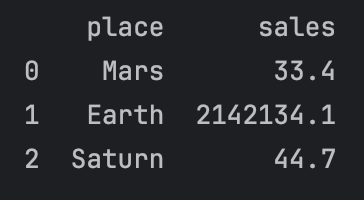
- Pandas 에서 row 값 가져오기
print(pd_df.iloc[[0,1]])
- Polars 에서 column 값 가져오기
print(pl_df.select("place",'sales'))
- Polars 에서 row 값 가져오기
print(pl_df[[0,1]])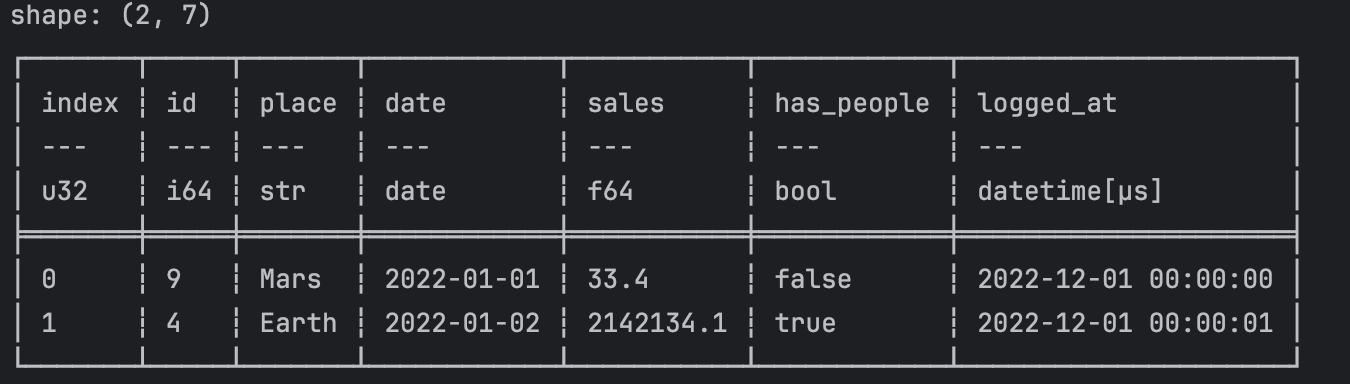
(4).Sorting
- Pandas
pd_df.sort_values("place", ascending=False)
- Polars
pl_df.sort(by='place', descending=True)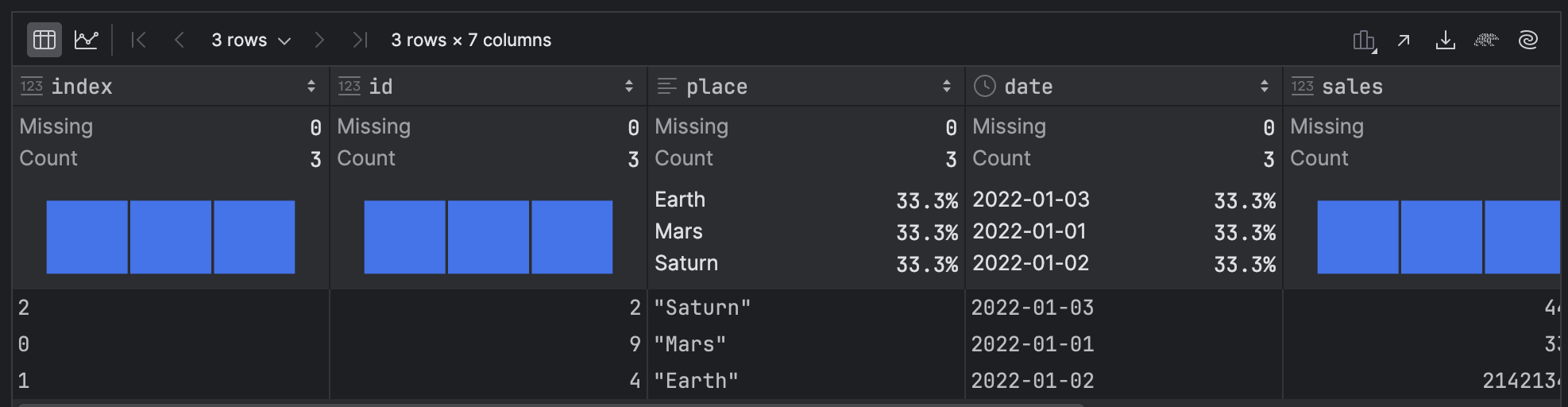
(5). Group by
- Pandas
pd_df.groupby('place').agg({"sales" : 'mean'})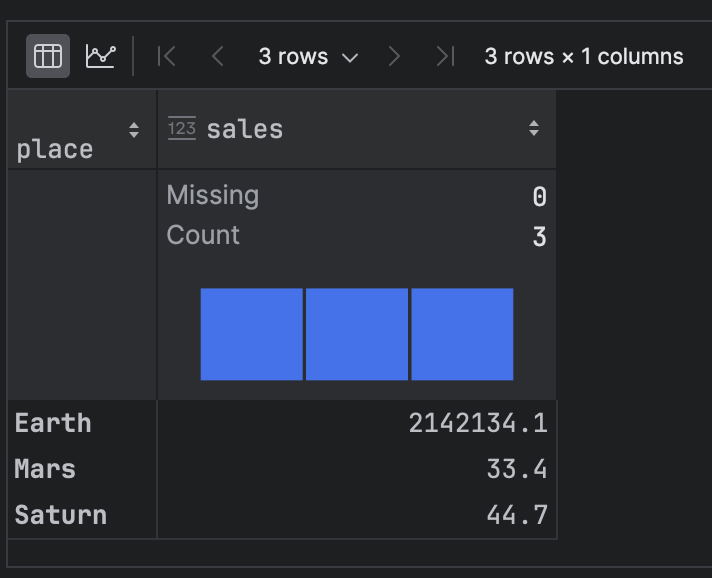
- Polars
pl_df.group_by('place').agg(pl.col('sales').mean())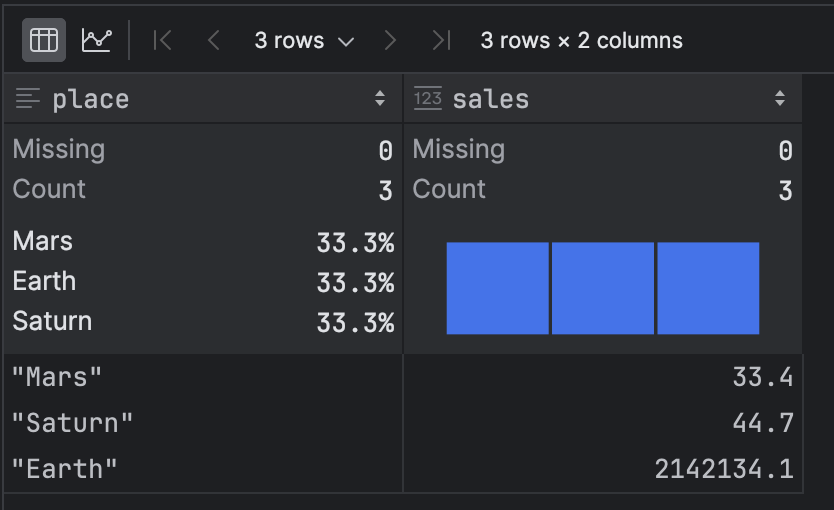
3. 그래서..
써보면서 확실히 속도도 빠르고 큼직큼직한 기능들은 Pandas와 유사해서 Pandas 같은 라이브러리면서 빠른 걸 찾는 사람들이라면 Polars가 적절하지 않을까 싶다. 한 가지 아쉬운 건 아직 만들어진지 얼마 안된 라이브러리라 그런건가? pandas의 info()나 데이터 프레임에서 value_count 같이 나름 쏠쏠한 기능들이 안들어와있는 것 같았다. 유사한 다른 기능이 있을 것 같기도하고..?
공식 문서가 아주 설명이 잘되어있어서 참고하면 사용하는데 무리는 없으리라 생각한다. 더 번창하는 북극곰이 되기를 바라며
공식 Docs
Index - Polars user guide
Blazingly Fast DataFrame Library Polars is a blazingly fast DataFrame library for manipulating structured data. The core is written in Rust, and available for Python, R and NodeJS. Key features Fast: Written from scratch in Rust, designed close to the mach
docs.pola.rs